
L’utilisation de la cryptographie n’a pas de finalité en soi : elle sert un objectif particulier qui peut varier suivant le contexte et s’insère dans le traitement de données que l’on souhaite protéger.
Dans quel ordre est-il plus pertinent de réaliser les opérations de chiffrement et de compression de données ?
On a alors un chance sur deux de se planter :
- Soit on répond « on compresse puis on chiffre »
- Soit on répond « on chiffre puis on compresse »
La réponse peut paraître évidente à certains mais détaillons. Pour répondre rappelons deux choses :
Comment chiffre-t-on des données ?
Le propre du chiffrement est de décoréler un maximum le message original (en clair) de sa version chiffrée afin d’éviter que l’attaquant puisse retrouver l’original s’il intercepte le chiffré.
Comment compresse-t-on des données ?
Les algorithmes classiques de compression au contraire utilisent la réccurrence (i.e: la fréquence) de certains blops dans les données.
Voici deux exemples triviaux de compression de données sans perte :
« CCCCCCC » => 7*C
« CryptoBourrinCrypto » => Crypto1/3Bourrin2
Bien évidemment, les algorithmes modernes de compressions sont bien plus élaborés que ces deux exemples simplistes. Mais ces derniers illustrent une des logiques utilisées pour stocker des données en minisant la taille de la mémoire utilisée.
Du coup, si nos données sont chiffrées, donc avec une entropie forte. Les algorithmes de compression seront peu voir pas du tout efficaces.
Ainsi voyez-vous la réponse s’impose d’elle même : il vaut mieux commencer par compresser les données puis les chiffrer si l’on veut optimiser la taille du résultat pour des transmissions ou stockages. Car compresser du chiffrer, ça ne sert pas à grand chose sauf quand on s’appelle Microsoft et qu’on utilise des archives compressés comme fichier pour sa suite bureautique.
Le cas de Microsoft Office
En effet, Ms Office depuis la version 2007, les extensions qui finissent en x (.docx, .xlsx, pptx, …) ne sont rien d’autres que des répertoires compressés. Nous pouvons donc les renommer en .zip et les ouvrir avec l’outils de Microsoft et comparer la version chiffrée et celle qui ne l’est pas. Regardons ce qui se passe dans le cas de l’utilisation de la fonction de confidentialité de Microsoft Word.
Nous avons rapidement créé un fichier Word et nous l’avons copié et chiffré la copie afin de comparer les tailles des deux fichiers puis nous avons ouvert l’archive de la version chiffré où on retrouve quelques méta-data et un « EncryptedPackage » faisant la même taille que le fichier originel.
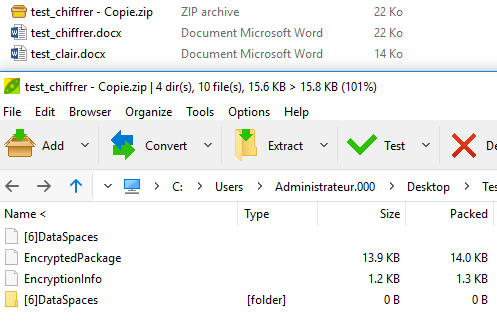
On ne détaillera pas ici le mécanisme de chiffrement d’Office qui mériterait bien un article à lui tout seul (un jour peut être). Mais nous voulions simplement voir comment il gérait le chiffrer/compresser : du coup nous avons la réponse : on compresse , on chiffre et on recompresse !
Un fichier chiffré peut-il être plus petit que sa version en clair ?
Avec de l’exemple précédent, certains nous diront que la réponse est évidente, le simple fait de chiffrer avec du symétrique par bloc c’est déjà rajouter a minima deux informations :
- un vecteur d’initialisation (car si c’est pour faire de l’ECB, autant ne rien faire)
- du bourrage à la fin du fichier
Ce n’est pas énorme mais cela suffit à avoir une taille strictement supérieure à l’original, suivant le mécanisme choisi on peut également avoir des entêtes (ou autre méta-données) à rajouter dans le fichier, mais parfois cela peut être un peu plus voir beaucou plus…
Le cas de S/MIME
Un grand classique pour illustrer cela est l’utilisation des messages S/MIME. En effet, le chiffrement peut poser problème en empéchant les messages de partir : Pas directement, mais par effet de bord. La plupart des systèmes de messagerie (notamment d’entreprise) ont des limites sur la taille du message qu’ils peuvent recevoir et transmettre pour des raisons tout à fait légitime de bon fonctionnement. Dans le cas contraire, imaginez les magnifiques attaques à base d’envoie de fichier de plusieurs giga, mais on s’éloigne du sujet.
Nous avons sur ce blog déjà abordé le S/MIME. Mais qu’il nous soit permis de rapidement rappeler que le S/MIME permet de chiffrer le contenu du corps d’un message MIME et ses pièces jointes. Rappelons aussi que le MIME est du pure ASCII, ainsi toutes les pièces jointes qui contiennent des caractères non imprimables sont convertis en base64 ce qui par définition multiple la taille du message par 4/3 mais si on rajoute le chiffrement qui s’applique au message en base64, le chiffrement rajoutant de l’entropie on se retrouve avec des caractères non-imprimables. On rajoute donc une nouvelle fois une conversion en base64 du chiffré soit une nouvelle augmentation de la taille du message de 4/3 : soit un total de 16/9.
Donc le chiffrement S/MIME multiplie la taille du message par 1,33 (1.78 par rapport aux pièces jointes) : c’est pas rien quand même !
Voilà, ce sont des petites considérations à garder en tête quand vous devez calmement expliquer au directeur financier que le chiffrement c’est bien, mais qu’il ne peut pas envoyer le bilan financier en S/MIME car le message est « tros gros » alors que tout le COMEX attend le document pour avant-hier…
Une petite image pour méditer pendant vos vacances :

